MINDSEARCH: MIMICKING HUMAN MINDS ELICITS DEEP AI SEARCHER
https://arxiv.org/pdf/2407.20183目录
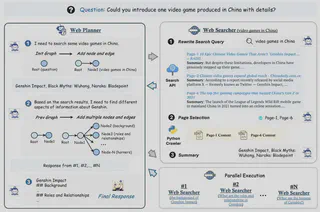
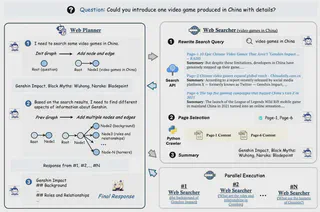
MindSearch框架中WebPlanner与WebSearcher的核心功能及协作机制
MindSearch是基于大语言模型(LLM)的多智能体框架,旨在模拟人类认知过程解决复杂网页信息检索与整合任务,其核心由WebPlanner(规划智能体)和WebSearcher(检索智能体)构成,二者通过分工协作突破传统搜索引擎与单一LLM的局限,实现高效、深度的信息处理。
一、WebPlanner的核心功能:模拟人类思维的“规划者”
WebPlanner对应人类解决复杂问题时的“拆解-推理-调度”认知过程,核心功能是将用户的复杂查询转化为可执行的分步任务,并通过动态图构建管理任务逻辑,具体包括以下3点:
1. 复杂查询的原子化拆解与动态图构建
WebPlanner将用户的复杂查询(如“分析嫦娥六号月球背面采样的技术挑战及与阿波罗11号的对比”)拆解为原子化子问题(如“嫦娥六号通信挑战”“阿波罗11号任务目标”“月球背面采样机械设计”等),并将这些子问题建模为有向无环图(DAG)的节点,节点间的有向边表示子问题的逻辑依赖关系(如“需先获取嫦娥六号采样流程,才能对比阿波罗11号的采样技术”)。
这种图结构并非静态,而是通过Python代码生成动态扩展:WebPlanner会根据已获取的WebSearcher检索结果,判断是否需要补充新子问题(如发现“月球背面导航”信息缺失时,自动添加对应节点),确保覆盖查询的深度与广度。
2. 任务调度与并行执行管理
WebPlanner通过DAG的拓扑关系识别无依赖的并行子任务(如“嫦娥六号的通信挑战”与“阿波罗11号的着陆技术”可同时检索),并将这些子任务分配给多个WebSearcher实例并行执行,大幅提升信息获取效率。
例如,在回答“2023年三大ML会议最佳论文总结”时,WebPlanner会同时调度3个WebSearcher分别检索NeurIPS、ICML、ICLR的最佳论文,而非串行执行,最终将多源结果整合为统一回答。
3. 全局逻辑把控与最终答案生成
WebPlanner不直接处理网页内容,而是专注于全局任务逻辑:它接收所有WebSearcher返回的子问题结果,检查信息完整性(如是否存在未覆盖的子问题、结果是否矛盾),若信息足够则生成“响应节点(Response Node)”,并基于所有子结果整合为结构化、逻辑连贯的最终答案;若存在信息缺口,则重新调度WebSearcher补充检索。
二、WebSearcher的核心功能:高效信息检索的“执行者”
WebSearcher对应人类使用搜索引擎获取具体信息的过程,核心功能是针对WebPlanner分配的子问题,通过分层检索策略从网页中提取高价值信息,解决“网页数量多、噪声大、LLM上下文超限”的问题,具体包括以下3点:
1. 子问题的多查询生成与召回增强
针对WebPlanner分配的单个子问题(如“嫦娥六号的通信挑战”),WebSearcher会生成多个相似查询(如“嫦娥六号 月球背面 通信方案”“Queqiao-2 relay satellite Chang’e-6”“嫦娥六号 地月通信中断 解决方法”),通过Google、Bing等搜索API执行多轮检索,避免因单一查询遗漏关键信息,提升相关网页的召回率。
2. 网页筛选与噪声过滤
搜索API返回的结果包含大量冗余网页(如无关新闻、重复内容),WebSearcher会先基于网页标题、摘要进行粗筛选,合并相同URL的结果,再调用LLM判断网页与子问题的相关性,筛选出最有价值的3-5个网页(而非处理所有结果),减少LLM的无效信息输入。
3. 深度信息提取与结构化总结
WebSearcher会获取筛选后网页的完整内容,调用LLM从中提取与子问题直接相关的信息(如技术参数、时间节点、核心结论),并以结构化格式(如分点、引用来源)返回给WebPlanner,同时标注信息来源,确保结果的可追溯性与事实性。
例如,针对“嫦娥六号的通信挑战”子问题,WebSearcher会从筛选后的网页中提取“月球背面无法直接通信”“依赖鹊桥二号中继卫星”“数据传输速率”等关键信息,而非返回完整网页文本。
三、WebPlanner与WebSearcher的协作流程
二者通过“规划-检索-反馈-整合”的闭环协作完成复杂任务,具体流程以“分析嫦娥六号月球背面采样技术挑战”为例,分为5步:
初始规划(WebPlanner):
WebPlanner接收用户查询后,拆解为3个核心子问题(节点):①月球背面通信挑战;②采样机械臂技术;③样本封装与返回流程,并构建初始DAG(根节点为用户查询,3个子节点为并行任务,无依赖关系)。任务分配(WebPlanner→WebSearcher):
WebPlanner通过Python代码调用3个WebSearcher实例,分别分配上述3个子问题,触发并行检索。分层检索(WebSearcher):
每个WebSearcher针对子问题生成多查询(如子问题①生成“嫦娥六号 通信中继”“Chang’e-6 far side communication”),执行搜索后筛选高相关网页(如中国探月工程官网、NASA技术报告),提取关键信息并标注来源,返回给WebPlanner。反馈与补全(WebPlanner→WebSearcher):
WebPlanner接收结果后,发现“样本返回过程中的热控技术”未被覆盖,补充新子问题节点,重新调度1个WebSearcher检索该内容,填补信息缺口。答案整合(WebPlanner):
所有子问题结果收集完毕后,WebPlanner生成“响应节点”,将通信挑战、机械臂技术、热控方案、样本封装等信息整合为逻辑连贯的回答,标注所有来源,最终输出给用户。
四、协作的核心优势
这种“规划者-执行者”的协作模式,本质上是将“复杂任务拆解”与“具体信息检索”的职责分离,带来两大核心优势:
- 效率提升:并行处理无依赖子问题,3分钟内可整合300+网页信息,相当于人类3小时的工作量;
- 质量保障:WebPlanner把控逻辑完整性,WebSearcher聚焦信息精准性,二者结合使回答在深度(如技术细节)、广度(如多维度覆盖)、事实性(如来源标注)上远超传统AI搜索工具(如ChatGPT-Web、Perplexity.ai)。